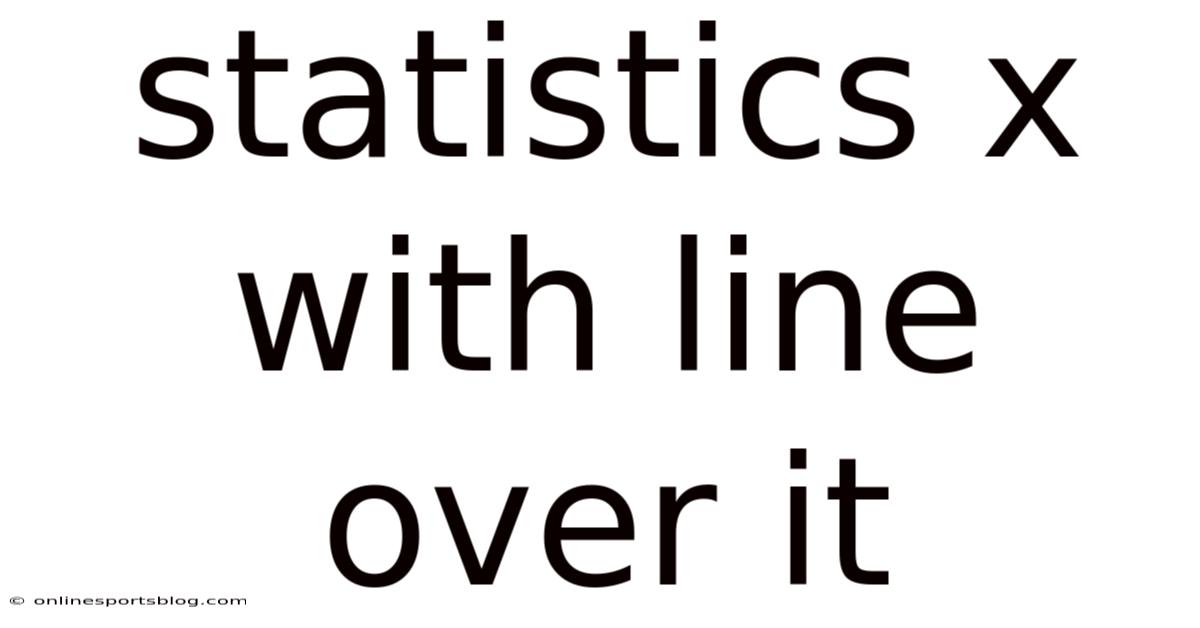
Understanding the Line Over X: The Role of the Sample Mean in Statistics
In the world of statistics, symbols and notations are essential tools for conveying complex ideas with precision. One such symbol, the line over X (denoted as X̄), plays a critical role in data analysis. Worth adding: this notation represents the sample mean, a fundamental concept in statistics that helps researchers summarize and interpret data. Whether you’re analyzing test scores, survey results, or experimental outcomes, the sample mean provides a central value that reflects the general trend of a dataset. In this article, we will explore what the line over X signifies, how it is calculated, its importance in statistical analysis, and its applications in real-world scenarios.
What is the Line Over X (X̄)?
The line over X (X̄) is a mathematical notation used to denote the sample mean. It is a statistical measure that represents the average value of a dataset. The "X" in this context stands for a variable, and the line over it indicates that we are calculating the mean of that variable across a sample of observations Small thing, real impact..
As an example, if you collect data on the heights of 50 students in a classroom, the X̄ would be the average height of those 50 students. This value serves as a single number that summarizes the entire dataset, making it easier to compare with other samples or populations Still holds up..
The sample mean is distinct from the population mean (denoted as μ), which represents the average of an entire population. Since it is often impractical to collect data from an entire population, statisticians rely on the sample mean to estimate the population mean It's one of those things that adds up..
How to Calculate the Sample Mean (X̄)
Calculating the sample mean is a straightforward process. Here’s a step-by-step guide:
- Collect Data: Gather the values of the variable you are studying. Take this case: if you are measuring the number of hours students spend studying per week, collect this data from a sample of students.
- Sum the Values: Add up all the individual data points.
- Divide by the Number of Observations: Divide the total sum by the number of data points in the sample.
The formula for the sample mean is:
X̄ = (ΣX) / n
Where:
- ΣX is the sum of all the data points.
- n is the number of data points in the sample.
Example: Suppose you have the following test scores from a sample of 5 students: 85, 90, 78, 92, and 88.
- Sum of scores: 85 + 90 + 78 + 92 + 88 = 433
- Number of students (n): 5
- Sample mean (X̄): 433 / 5 = 86.6
This means the average test score in this sample is 86.6.
Why is the Sample Mean Important?
The sample mean is a cornerstone of statistical analysis because it provides a concise summary of a dataset. Here are some key reasons why it is essential:
- Simplifies Complex Data: Instead of analyzing every individual data point, the sample mean allows researchers to focus on a single value that represents the central tendency of the data.
- Enables Comparisons: By calculating the sample mean for different groups, researchers can compare their central tendencies. As an example, comparing the average income of two cities helps identify economic disparities.
- Supports Inferential Statistics: The sample mean is used to make inferences about a larger population. To give you an idea, if a pharmaceutical company tests a new drug on a sample of patients, the sample mean of recovery times can be used to estimate the drug’s effectiveness in the general population.
- Foundation for Other Statistical Measures: The sample mean is often the starting point for calculating other statistical measures, such as variance, standard deviation, and confidence intervals.
Applications of the Sample Mean in Real-World Scenarios
The sample mean is widely used across various fields, from business to healthcare. Here are a few examples:
- Market Research: Companies use the sample mean to estimate customer preferences. Take this case: a survey of 1,000 customers might reveal an average satisfaction score of 4.2 out of 5, which helps businesses improve their products.
- Healthcare: In clinical trials, the sample mean of a treatment’s effectiveness is calculated to determine whether a new medication is likely to benefit the broader population.
- Education: Teachers use the sample mean to assess student performance. If the average test score in a class is 75, educators can identify areas where students may need additional support.
- Quality Control: Manufacturers use the sample mean to monitor product quality. By analyzing the average weight of
Extending the Concept toQuality Assurance
When manufacturers evaluate the consistency of a production line, they often draw a random sample of finished items and compute the sample mean of a critical attribute—such as weight, diameter, or fill volume. By monitoring how this mean shifts over successive samples, engineers can detect drift that signals a machine may be out of calibration.
Take this case: imagine a snack‑food plant that aims for each bag to contain 150 g of product. Over the course of an hour, a quality technician pulls ten random bags and records their weights:
148.2, 151.7, 149.5, 152.1, 147.9, 150.3, 149.8, 151.4, 148.9, 150.7
The arithmetic average of these observations is
[\bar{x}= \frac{148.2+151.7+149.5+152.1+147.9+150.3+149.8+151.4+148.9+150.7}{10}=150.0\text{ g} ]
If subsequent batches consistently yield a mean that deviates by more than a pre‑specified tolerance—say, ±0.5 g—the control chart triggers an investigation. The deviation may stem from a worn‑out feeder, temperature fluctuation, or raw‑material variability, prompting corrective maintenance before defective products reach consumers It's one of those things that adds up. Worth knowing..
From a Single Mean to a Confidence Interval
A solitary sample mean provides a point estimate, but it carries uncertainty because it is derived from a limited set of observations. To express this uncertainty, statisticians construct a confidence interval (CI) around the mean. Assuming the underlying attribute follows a normal distribution and the sample size is moderate, a 95 % CI is calculated as
[ \bar{x} \pm t_{\alpha/2,,df},\frac{s}{\sqrt{n}} ]
where (s) is the sample standard deviation, (n) the sample size, and (t_{\alpha/2,,df}) the critical value from the t‑distribution with (df=n-1) degrees of freedom.
Returning to the snack‑bag example, suppose the computed standard deviation of the ten weights is (s = 1.In practice, 2) g. In practice, 025,9}) ≈ 2. Also, with (n=10) and a 95 % confidence level, the multiplier (t_{0. 262.
[ 150.Practically speaking, 0 \pm 2. 2}{\sqrt{10}} ;=;150.262 \times \frac{1.0 \pm 0.
Thus, we can be 95 % confident that the true average weight of all bags produced during that shift lies between 149.14 g and 150.Also, 86 g. If the target 150 g falls near the interval’s edge, the process may still be considered acceptable, but a systematic shift toward the lower bound would warrant immediate attention And it works..
Linking the Sample Mean to Hypothesis Testing
Quality engineers frequently need to answer binary questions: *Is the current process producing items at the desired specification, or has it drifted?Even so, the null hypothesis (H_0) typically asserts that the population mean equals a target value (\mu_0) (e. * This is formalized through hypothesis testing. g.Day to day, , 150 g). The alternative hypothesis (H_a) posits a deviation—either less than, greater than, or simply not equal to (\mu_0) Not complicated — just consistent. Nothing fancy..
Short version: it depends. Long version — keep reading.
Using the same ten‑bag sample, the test statistic is
[ t = \frac{\bar{x} - \mu_0}{s/\sqrt{n}} ]
If the calculated (t) exceeds the critical value for the chosen significance level (commonly 0.05), the null hypothesis is rejected, indicating statistically significant evidence of a shift. In practice, software packages automate this calculation, but the underlying logic always hinges on the sample mean as the central statistic.
Beyond manufacturing, the sample mean underpins decision‑making in diverse arenas:
- Finance: Analysts compute the average return of a portfolio over a rolling window to assess performance trends and to compare against benchmark indices.
- Environmental Science: Researchers average pollutant concentrations across monitoring stations to evaluate compliance with regulatory limits.
- Human Resources: Companies benchmark employee turnover rates by averaging exit interview scores, guiding interventions to improve retention.
In each case
Understanding the statistical framework behind confidence intervals and hypothesis testing empowers professionals across sectors to make informed decisions with confidence. Even so, by applying the same principles—such as interpreting the t‑value and confidence bounds—teams can assess whether observed results align with expectations or signal meaningful change. And the snack‑bag scenario illustrates how real data, when analyzed rigorously, reveals subtle shifts that demand attention. Think about it: similarly, in broader contexts, the sample mean serves as a central measure, guiding whether processes remain within acceptable ranges or require corrective action. Mastery of these tools not only enhances analytical precision but also strengthens the reliability of conclusions across industries. To keep it short, leveraging statistical insights ensures that data-driven strategies are both sound and actionable. Conclusion: Embracing these methods fosters a culture of vigilance and accuracy, essential for sustained quality and performance.